Facebook Graph API Methods and Parameters
11 Jul 2013Quick reference for available Facebook Graph API actions with accompanying parameters:
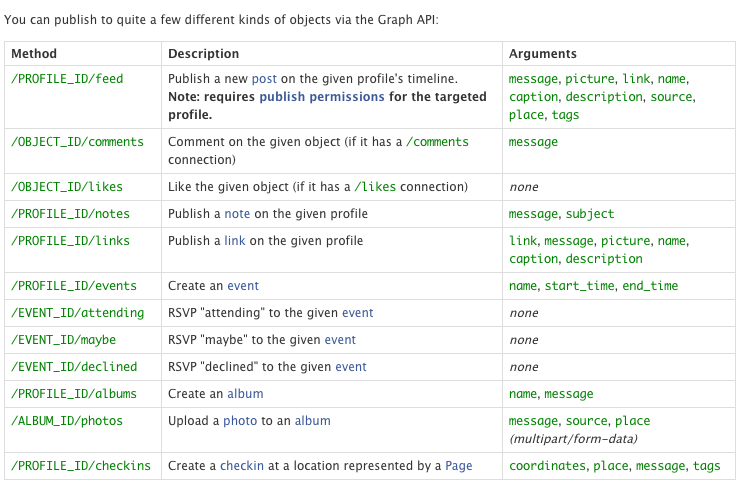

Quick reference for available Facebook Graph API actions with accompanying parameters:
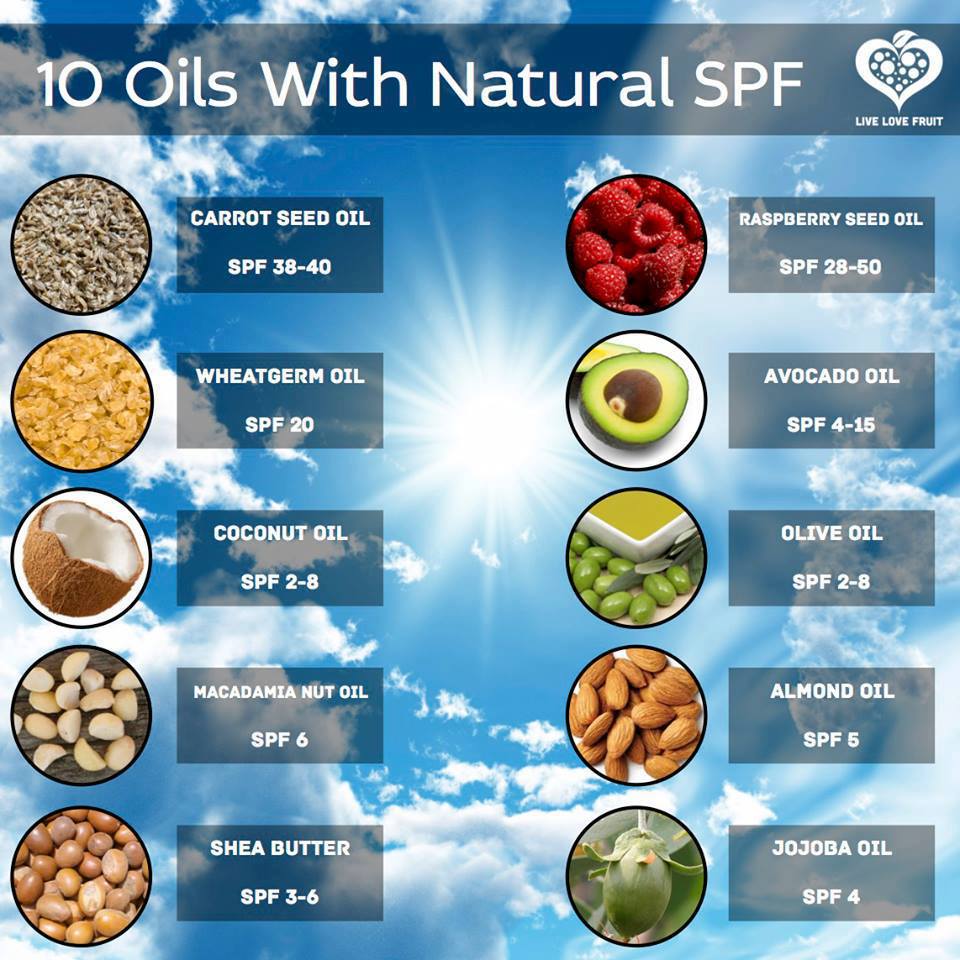
These are the natural oils that can be used as SPF protection agains bad UV rays. It should be much more healthy than using a sun block as the sun block itself is cancerogenic substance
Great open source map clustering library by TwoToasters
Check out the video of sample application in action
This nice sliding menu is supported in its full glory with API level 14. But can be degraded gracefully on earlier version of the OS too.
Tip from Romain: use the drawing cache instead with View.setDrawingCacheEnabled.
Every time a start session is called using Flurry SDK, a new session is registered unless the call was made within 20 seconds [for the same user] of the previous call, in which case these consequent sessions simply extend the existing one.
For Google Analytics, it is different. Google Analytics will group hits (any analytics API call you make is considered a hit in Google analytics) that are received within 30 minutes of one another [for the same user] into the same session.
Here's a nice project to be able to work with Android APK resources:
Here's how to use Vim as a handy HEX editor:
:% ! xxd</li>
:% ! xxd -r</li>
Microsoft’s strategy should not be to produce a better phone or tablet or to be the best mobile content provider. It cannot out-Apple Apple.
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| API_EC_SUCCESS | Success | (all) | |
| 1 | API_EC_UNKNOWN | An unknown error occurred | (all) |
| 2 | API_EC_SERVICE | Service temporarily unavailable | (all) |
| 3 | API_EC_METHOD | Unknown method | |
| 4 | API_EC_TOO_MANY_CALLS | Application request limit reached | (all) |
| 5 | API_EC_BAD_IP | Unauthorized source IP address | (all) |
| 6 | API_EC_HOST_API | This method must run on api.facebook.com | (all) |
| 7 | API_EC_HOST_UP | This method must run on api-video.facebook.com | |
| 8 | API_EC_SECURE | This method requires an HTTPS connection | |
| 9 | API_EC_RATE | User is performing too many actions | |
| 10 | API_EC_PERMISSION_DENIED | Application does not have permission for this action | |
| 11 | API_EC_DEPRECATED | This method is deprecated | |
| 12 | API_EC_VERSION | This API version is deprecated | |
| 13 | API_EC_INTERNAL_FQL_ERROR | The underlying FQL query made by this API call has encountered an error. Please check that your parameters are correct. | |
| 14 | API_EC_HOST_PUP | This method must run on api-photo.facebook.com | |
| 15 | API_EC_SESSION_SECRET_NOT_ALLOWED | This method call must be signed with the application secret (You are probably calling a secure method using a session secret) | |
| 16 | API_EC_HOST_READONLY | This method cannot be run on this host, which only supports read-only calls | |
| 17 | API_EC_USER_TOO_MANY_CALLS | User request limit reached | |
| 18 | API_EC_REQUEST_RESOURCES_EXCEEDED | This API call could not be completed due to resource limits |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 100 | API_EC_PARAM | Invalid parameter | (all) |
| 101 | API_EC_PARAM_API_KEY | Invalid API key | (all) |
| 102 | API_EC_PARAM_SESSION_KEY | Session key invalid or no longer valid | (all) |
| 103 | API_EC_PARAM_CALL_ID | Call_id must be greater than previous | |
| 104 | API_EC_PARAM_SIGNATURE | Incorrect signature | (all) |
| 105 | API_EC_PARAM_TOO_MANY | The number of parameters exceeded the maximum for this operation | |
| 110 | API_EC_PARAM_USER_ID | Invalid user id | photos.addTag |
| 111 | API_EC_PARAM_USER_FIELD | Invalid user info field | |
| 112 | API_EC_PARAM_SOCIAL_FIELD | Invalid user field | |
| 113 | API_EC_PARAM_EMAIL | Invalid email | |
| 114 | API_EC_PARAM_USER_ID_LIST | Invalid user ID list | |
| 115 | API_EC_PARAM_FIELD_LIST | Invalid field list | |
| 120 | API_EC_PARAM_ALBUM_ID | Invalid album id | |
| 121 | API_EC_PARAM_PHOTO_ID | Invalid photo id | |
| 130 | API_EC_PARAM_FEED_PRIORITY | Invalid feed publication priority | |
| 140 | API_EC_PARAM_CATEGORY | Invalid category | |
| 141 | API_EC_PARAM_SUBCATEGORY | Invalid subcategory | |
| 142 | API_EC_PARAM_TITLE | Invalid title | |
| 143 | API_EC_PARAM_DESCRIPTION | Invalid description | |
| 144 | API_EC_PARAM_BAD_JSON | Malformed JSON string | |
| 150 | API_EC_PARAM_BAD_EID | Invalid eid | |
| 151 | API_EC_PARAM_UNKNOWN_CITY | Unknown city | |
| 152 | API_EC_PARAM_BAD_PAGE_TYPE | Invalid page type | |
| 170 | API_EC_PARAM_BAD_LOCALE | Invalid locale | |
| 180 | API_EC_PARAM_BLOCKED_NOTIFICATION | This notification was not delieved | |
| 190 | API_EC_PARAM_ACCESS_TOKEN | Invalid OAuth 2.0 Access Token |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 200 | API_EC_PERMISSION | Permissions error | |
| 210 | API_EC_PERMISSION_USER | User not visible | |
| 211 | API_EC_PERMISSION_NO_DEVELOPERS | Application has no developers. | admin.setAppProperties |
| 212 | API_EC_PERMISSION_OFFLINE_ACCESS | Renewing a session offline requires the extended permission offline_access | |
| 220 | API_EC_PERMISSION_ALBUM | Album or albums not visible | |
| 221 | API_EC_PERMISSION_PHOTO | Photo not visible | |
| 230 | API_EC_PERMISSION_MESSAGE | Permissions disallow message to user | |
| 240 | API_EC_PERMISSION_MARKUP_OTHER_USER | Desktop applications cannot set FBML for other users | |
| 250 | API_EC_PERMISSION_STATUS_UPDATE | Updating status requires the extended permission status_update. | users.setStatus |
| 260 | API_EC_PERMISSION_PHOTO_UPLOAD | Modifying existing photos requires the extended permission photo_upload | photos.upload,photos.addTag |
| 261 | API_EC_PERMISSION_VIDEO_UPLOAD | Modifying existing photos requires the extended permission photo_upload | photos.upload,photos.addTag |
| 270 | API_EC_PERMISSION_SMS | Permissions disallow sms to user. | |
| 280 | API_EC_PERMISSION_CREATE_LISTING | Creating and modifying listings requires the extended permission create_listing | |
| 281 | API_EC_PERMISSION_CREATE_NOTE | Managing notes requires the extended permission create_note. | |
| 282 | API_EC_PERMISSION_SHARE_ITEM | Managing shared items requires the extended permission share_item. | |
| 290 | API_EC_PERMISSION_EVENT | Creating and modifying events requires the extended permission create_event | events.create, events.edit |
| 291 | API_EC_PERMISSION_LARGE_FBML_TEMPLATE | FBML Template isn\’t owned by your application. | |
| 292 | API_EC_PERMISSION_LIVEMESSAGE | An application is only allowed to send LiveMessages to users who have accepted the TOS for that application. | liveMessage.send |
| 293 | API_EC_PERMISSION_XMPP_LOGIN | Logging in to chat requires the extended permission xmpp_login | Integrating with FacebookChat |
| 294 | API_EC_PERMISSION_ADS_MANAGEMENT | Managing advertisements requires the extended permission ads_management, and a participating API key | Ads API |
| 296 | API_EC_PERMISSION_CREATE_EVENT | Managing events requires the extended permission create_event | API#Events_API_Methods |
| 298 | API_EC_PERMISSION_READ_MAILBOX | Reading mailbox messages requires the extended permission read_mailbox | message.getThreadsInFolder |
| 299 | API_EC_PERMISSION_RSVP_EVENT | RSVPing to events requires the extended permission create_rsvp | events.rsvp |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 300 | API_EC_EDIT | Edit failure | |
| 310 | API_EC_EDIT_USER_DATA | User data edit failure | |
| 320 | API_EC_EDIT_PHOTO | Photo edit failure | |
| 321 | API_EC_EDIT_ALBUM_SIZE | Album is full | |
| 322 | API_EC_EDIT_PHOTO_TAG_SUBJECT | Invalid photo tag subject | |
| 323 | API_EC_EDIT_PHOTO_TAG_PHOTO | Cannot tag photo already visible on Facebook | |
| 324 | API_EC_EDIT_PHOTO_FILE | Missing or invalid image file | |
| 325 | API_EC_EDIT_PHOTO_PENDING_LIMIT | Too many unapproved photos pending | |
| 326 | API_EC_EDIT_PHOTO_TAG_LIMIT | Too many photo tags pending | |
| 327 | API_EC_EDIT_ALBUM_REORDER_PHOTO_NOT_IN_ALBUM | Input array contains a photo not in the album | |
| 328 | API_EC_EDIT_ALBUM_REORDER_TOO_FEW_PHOTOS | Input array has too few photos | |
| 329 | API_EC_MALFORMED_MARKUP | Template data must be a JSON-encoded dictionary, of the form </p> {'key-1': 'value-1', 'key-2': 'value-2', ...} | |
| 330 | API_EC_EDIT_MARKUP | Failed to set markup | |
| 340 | API_EC_EDIT_FEED_TOO_MANY_USER_CALLS | Feed publication request limit reached | |
| 341 | API_EC_EDIT_FEED_TOO_MANY_USER_ACTION_CALLS | Feed action request limit reached | |
| 342 | API_EC_EDIT_FEED_TITLE_LINK | Feed story title can have at most one href anchor | |
| 343 | API_EC_EDIT_FEED_TITLE_LENGTH | Feed story title is too long | |
| 344 | API_EC_EDIT_FEED_TITLE_NAME | Feed story title can have at most one fb:userlink and must be of the user whose action is being reported | |
| 345 | API_EC_EDIT_FEED_TITLE_BLANK | Feed story title rendered as blank | |
| 346 | API_EC_EDIT_FEED_BODY_LENGTH | Feed story body is too long | |
| 347 | API_EC_EDIT_FEED_PHOTO_SRC | Feed story photo could not be accessed or proxied | |
| 348 | API_EC_EDIT_FEED_PHOTO_LINK | Feed story photo link invalid | |
| 350 | API_EC_EDIT_VIDEO_SIZE | Video file is too large | video.upload |
| 351 | API_EC_EDIT_VIDEO_INVALID_FILE | Video file was corrupt or invalid | video.upload |
| 352 | API_EC_EDIT_VIDEO_INVALID_TYPE | Video file format is not supported | video.upload |
| 353 | API_EC_EDIT_VIDEO_FILE | Missing video file | video.upload |
| 354 | API_EC_EDIT_VIDEO_NOT_TAGGED | User is not tagged in this video | |
| 355 | API_EC_EDIT_VIDEO_ALREADY_TAGGED | User is already tagged in this video | |
| 360 | API_EC_EDIT_FEED_TITLE_ARRAY | Feed story title_data argument was not a valid JSON-encoded array | |
| 361 | API_EC_EDIT_FEED_TITLE_PARAMS | Feed story title template either missing required parameters, or did not have all parameters defined in title_data array | |
| 362 | API_EC_EDIT_FEED_BODY_ARRAY | Feed story body_data argument was not a valid JSON-encoded array | |
| 363 | API_EC_EDIT_FEED_BODY_PARAMS | Feed story body template either missing required parameters, or did not have all parameters defined in body_data array | |
| 364 | API_EC_EDIT_FEED_PHOTO | Feed story photos could not be retrieved, or bad image links were provided | |
| 365 | API_EC_EDIT_FEED_TEMPLATE | The template for this story does not match any templates registered for this application | |
| 366 | API_EC_EDIT_FEED_TARGET | One or more of the target ids for this story are invalid. They must all be ids of friends of the acting user | |
| 367 | API_EC_EDIT_FEED_MARKUP | The template data provided doesn’t cover the entire token set needed to publish the story | |
| 370 | API_EC_USERS_CREATE_INVALID_EMAIL | The email address you provided is not a valid email address | |
| 371 | API_EC_USERS_CREATE_EXISTING_EMAIL | The email address you provided belongs to an existing account | |
| 372 | API_EC_USERS_CREATE_BIRTHDAY | The birthday provided is not valid | |
| 373 | API_EC_USERS_CREATE_PASSWORD | The password provided is too short or weak | |
| 374 | API_EC_USERS_REGISTER_INVALID_CREDENTIAL | The login credential you provided is invalid. | |
| 375 | API_EC_USERS_REGISTER_CONF_FAILURE | Failed to send confirmation message to the specified login credential. | |
| 376 | API_EC_USERS_REGISTER_EXISTING | The login credential you provided belongs to an existing account | |
| 377 | API_EC_USERS_REGISTER_DEFAULT_ERROR | Sorry, we were unable to process your registration. | |
| 378 | API_EC_USERS_REGISTER_PASSWORD_BLANK | Your password cannot be blank. Please try another. | |
| 379 | API_EC_USERS_REGISTER_PASSWORD_INVALID_CHARS | Your password contains invalid characters. Please try another. | |
| 380 | API_EC_USERS_REGISTER_PASSWORD_SHORT | Your password must be at least 6 characters long. Please try another. | |
| 381 | API_EC_USERS_REGISTER_PASSWORD_WEAK | Your password should be more secure. Please try another. | |
| 382 | API_EC_USERS_REGISTER_USERNAME_ERROR | Our automated system will not approve this name. | |
| 383 | API_EC_USERS_REGISTER_MISSING_INPUT | You must fill in all of the fields. | |
| 384 | API_EC_USERS_REGISTER_INCOMPLETE_BDAY | You must indicate your full birthday to register. | |
| 385 | API_EC_USERS_REGISTER_INVALID_EMAIL | Please enter a valid email address. | |
| 386 | API_EC_USERS_REGISTER_EMAIL_DISABLED | The email address you entered has been disabled. Please contact disabled@facebook.com with any questions. | |
| 387 | API_EC_USERS_REGISTER_ADD_USER_FAILED | There was an error with your registration. Please try registering again. | |
| 388 | API_EC_USERS_REGISTER_NO_GENDER | Please select either Male or Female. |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 400 | API_EC_AUTH_EMAIL | Invalid email address | |
| 401 | API_EC_AUTH_LOGIN | Invalid username or password | |
| 402 | API_EC_AUTH_SIG | Invalid application auth sig | |
| 403 | API_EC_AUTH_TIME | Invalid timestamp for authentication |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 450 | API_EC_SESSION_TIMED_OUT | Session key specified has passed its expiration time | |
| 451 | API_EC_SESSION_METHOD | Session key specified cannot be used to call this method | |
| 452 | API_EC_SESSION_INVALID | Session key invalid. This could be because the session key has an incorrect format, or because the user has revoked this session | |
| 453 | API_EC_SESSION_REQUIRED | A session key is required for calling this method | |
| 454 | API_EC_SESSION_REQUIRED_FOR_SECRET | A session key must be specified when request is signed with a session secret | |
| 455 | API_EC_SESSION_CANNOT_USE_SESSION_SECRET | A session secret is not permitted to be used with this type of session key |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 500 | API_EC_MESG_BANNED | Message contains banned content | |
| 501 | API_EC_MESG_NO_BODY | Missing message body | |
| 502 | API_EC_MESG_TOO_LONG | Message is too long | |
| 503 | API_EC_MESG_RATE | User has sent too many messages | |
| 504 | API_EC_MESG_INVALID_THREAD | Invalid reply thread id | |
| 505 | API_EC_MESG_INVALID_RECIP | Invalid message recipient | |
| 510 | API_EC_POKE_INVALID_RECIP | Invalid poke recipient | |
| 511 | API_EC_POKE_OUTSTANDING | There is a poke already outstanding | |
| 512 | API_EC_POKE_RATE | User is poking too fast | |
| 513 | API_EC_POKE_USER_BLOCKED | User cannot poke via API |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 600 | FQL_EC_UNKNOWN_ERROR | An unknown error occurred in FQL | fql.query,fql.multiquery |
| 601 | FQL_EC_PARSER_ERROR | Error while parsing FQL statement | fql.query,fql.multiquery |
| 602 | FQL_EC_UNKNOWN_FIELD | The field you requested does not exist | fql.query,fql.multiquery |
| 603 | FQL_EC_UNKNOWN_TABLE | The table you requested does not exist | fql.query,fql.multiquery |
| 604 | FQL_EC_NO_INDEX | Your statement is not indexable | fql.query,fql.multiquery |
| 605 | FQL_EC_UNKNOWN_FUNCTION | The function you called does not exist | fql.query,fql.multiquery |
| 606 | FQL_EC_INVALID_PARAM | Wrong number of arguments passed into the function | fql.query,fql.multiquery |
| 607 | FQL_EC_INVALID_FIELD | FQL field specified is invalid in this context. | fql.query*,fql.multiquery |
| 608 | FQL_EC_INVALID_SESSION | An invalid session was specified | fql.query,fql.multiquery |
| 609 | FQL_EC_UNSUPPORTED_APP_TYPE | FQL field specified is invalid in this context. | fql.query*,fql.multiquery |
| 610 | FQL_EC_SESSION_SECRET_NOT_ALLOWED | FQL field specified is invalid in this context. | fql.query*,fql.multiquery |
| 611 | FQL_EC_DEPRECATED_TABLE | FQL field specified is invalid in this context. | fql.query*,fql.multiquery |
| 612 | FQL_EC_EXTENDED_PERMISSION | The stream requires an extended permission | fql.query,fql.multiquery |
| 613 | FQL_EC_RATE_LIMIT_EXCEEDED | Calls to stream have exceeded the rate of 100 calls per 600 seconds. | fql.query,fql.multiquery |
| 614 | FQL_EC_UNRESOLVED_DEPENDENCY | Unresolved dependency in multiquery | fql.multiquery |
| 615 | FQL_EC_INVALID_SEARCH | This search is invalid | fql.query,fql.multiquery |
| 617 | FQL_EC_TOO_MANY_FRIENDS_FOR_PRELOAD | The user you queried against has too many friends to be used with Preload FQL, in order to avoid out of memory errors | fql.query,fql.multiquery |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 700 | API_EC_REF_SET_FAILED | Unknown failure in storing ref data. Please try again. |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 750 | API_EC_FB_APP_UNKNOWN_ERROR | Unknown Facebook application integration failure. | |
| 751 | API_EC_FB_APP_FETCH_FAILED | Fetch from remote site failed. | |
| 752 | API_EC_FB_APP_NO_DATA | Application returned no data. This may be expected or represent a connectivity error. | |
| 753 | API_EC_FB_APP_NO_PERMISSIONS | Application returned user had invalid permissions to complete the operation. | |
| 754 | API_EC_FB_APP_TAG_MISSING | Application returned data, but no matching tag found. This may be expected. | |
| 755 | API_EC_FB_APP_DB_FAILURE | The database for this object failed. |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 900 | API_EC_NO_SUCH_APP | No such application exists. | application.getPublicInfo |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 950 | API_BATCH_TOO_MANY_ITEMS | Each batch API can not contain more than 20 items | |
| 951 | API_EC_BATCH_ALREADY_STARTED | begin_batch already called, please make sure to call end_batch first. | |
| 952 | API_EC_BATCH_NOT_STARTED | end_batch called before begin_batch. | |
| 953 | API_EC_BATCH_METHOD_NOT_ALLOWED_IN_BATCH_MODE | This method is not allowed in batch mode. |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1000 | API_EC_EVENT_INVALID_TIME | Invalid time for an event. | events.edit |
| 1001 | API_EC_EVENT_NAME_LOCKED | You are no longer able to change the name of this event. | events.edit |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1100 | API_EC_LIVEMESSAGE_SEND_FAILED | An error occurred while sending the LiveMessage. | liveMessage.send |
| 1101 | API_EC_LIVEMESSAGE_EVENT_NAME_TOO_LONG | The event_name parameter must be no longer than 128 bytes. | liveMessage.send |
| 1102 | API_EC_LIVEMESSAGE_MESSAGE_TOO_LONG | The message parameter must be no longer than 1024 bytes. | liveMessage.send |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1200 | API_EC_CHAT_SEND_FAILED | An error occurred while sending the message. |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1201 | API_EC_PAGES_CREATE | You have created too many pages |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1500 | API_EC_SHARE_BAD_URL | The url you supplied is invalid |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1600 | API_EC_NOTE_CANNOT_MODIFY | The user does not have permission to modify this note. |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1700 | API_EC_COMMENTS_UNKNOWN | An unknown error has occurred. | |
| 1701 | API_EC_COMMENTS_POST_TOO_LONG | The specified post was too long. | |
| 1702 | API_EC_COMMENTS_DB_DOWN | The comments database is down. | |
| 1703 | API_EC_COMMENTS_INVALID_XID | The specified xid is not valid. xids can only contain letters, numbers, and underscores | |
| 1704 | API_EC_COMMENTS_INVALID_UID | The specified user is not a user of this application | |
| 1705 | API_EC_COMMENTS_INVALID_POST | There was an error during posting. | |
| 1706 | API_EC_COMMENTS_INVALID_REMOVE | While attempting to remove the post. |
| Error code | Error message | Note | Generated by methods |
|---|---|---|---|
| 1383001 | Unknown | Facebook system issue. | |
| 1383002 | InvalidParameters | Developer called with the incorrect parameters. | |
| 1383003 | PaymentFailure | Processor decline. | |
| 1383004 | InvalidOperation | Developer attempted an operation Facebook does not allow. | |
| 1383005 | PermissionDenied | Facebook system issue. | |
| 1383006 | DatabaseError | Facebook system issue. | |
| 1383007 | InvalidApp | App is not whitelisted. Or while in test mode, Developer attempted to debit a user that was not whitelisted. | |
| 1383008 | AppNoResponse | App is not responding; perhaps a server timeout issue. | |
| 1383009 | AppErrorResponse | App responded to Facebook with an error code. | |
| 1383010 | UserCanceled | User explicitly cancelled out of flow. | |
| 1383011 | Disabled | Facebook system issue. | |
| 1383013 | OrderFailureAfterPurchaseCredit | Facebook system issue. | |
| 1383014 | DisputeFlow | Facebook system issue. | |
| 1383015 | AccountNotCharged | Your application cancelled the order. | |
| 1383017 | ExceedCreditBalanceLimit | Reached maximum number of credits the user is allowed to keep as a stored balance. This is a Facebook controlled limit and can vary from user to user. | |
| 1383018 | ExceedCreditDailyPurchaseLimit | Occurs when a user has reached a predefined daily maximum | |
| 1383019 | ExceedCreditDailySpendLimit | Occurs when the credit amount user spends in a single day exceeds a pre-defined threshold. | |
| 1383040 | UserThrottled | Application Temporarily Unavailable | |
| 1383041 | BuyerPaymentFailure | User’s financial instrument could not be charged. | |
| 1383042 | LoggedOutUser | Login Required | |
| 1383043 | AppInfoFetchFailure | Facebook system error. | |
| 1383044 | InvalidAppInfo | Application needs to have a valid callback url. | |
| 1383045 | AppInvalidEncodedResponse | The application didn’t return a valid json encoded response.. | |
| 1383046 | AppInvalidDecodedResponse | The application return value was invalid after json_decoding the return value. | |
| 1383047 | AppInvalidMethodResponse | The application response contains a ‘method’ parameter that didn’t match the request. | |
| 1383048 | AppMissingContentResponse | The application response didn’t contain the ‘content’ field. | |
| 1383049 | AppUnknownResponseError | The application returned an unknown response. | |
| 1383050 | AppUserValidationFailedResponse | Failure to verify the user when sending application callback. | |
| 1383051 | AppInvalidItemParam | The application is sending invalid item parameters (For example, price or quantity of the items is invalid). | |
| 1383052 | EmptyAppId | Empty App ID. |
| Error code | Error message | Note | Generated by methods |
|---|---|---|---|
| 1150 | API_EC_PAYMENTS_UNKNOWN | Unknown error | |
| 1151 | API_EC_PAYMENTS_APP_INVALID | Application is not enabled for using Facebook Credits. | |
| 1152 | API_EC_PAYMENTS_DATABASE | A database error occurred. | |
| 1153 | API_EC_PAYMENTS_PERMISSION_DENIED | Permission denied to check order details. | |
| 1154 | API_EC_PAYMENTS_APP_NO_RESPONSE | Payments callback to the application failed. | |
| 1155 | API_EC_PAYMENTS_APP_ERROR_RESPONSE | Payments callback to the application received error response. | |
| 1156 | API_EC_PAYMENTS_INVALID_ORDER | The supplied order ID is invalid. | |
| 1157 | API_EC_PAYMENTS_INVALID_PARAM | One of the Payments parameters is invalid. | |
| 1158 | API_EC_PAYMENTS_INVALID_OPERATION | The operation is invalid. | |
| 1159 | API_EC_PAYMENTS_PAYMENT_FAILED | Failed in processing the payment. | |
| 1160 | API_EC_PAYMENTS_DISABLED | Facebook Credits system is disabled. | |
| 1161 | API_EC_PAYMENTS_INSUFFICIENT_BALANCE | Insufficient balance. | |
| 1162 | API_EC_PAYMENTS_EXCEED_CREDIT_BALANCE_LIMIT | Exceed credit balance limit. | |
| 1163 | API_EC_PAYMENTS_EXCEED_CREDIT_DAILY_PURCHASE_LIMIT | Exceed daily credit purchase limit. | |
| 1164 | API_EC_PAYMENTS_EXCEED_CREDIT_DAILY_SPEND_LIMIT | Exceed daily credit spend limit. | |
| 1166 | API_EC_PAYMENTS_INVALID_FUNDING_AMOUNT | Credits purchased from funding source do not match the spend order amount. | |
| 1167 | API_EC_PAYMENTS_NON_REFUNDABLE_PAYMENT_METHOD | The funding source is a non-refundable payment method. | |
| 1168 | API_EC_PAYMENTS_USER_THROTTLED | Application is configured to throttle some users. | |
| 1169 | API_EC_PAYMENTS_LOGIN_REQUIRED | User is not logged in. | |
| 1170 | API_EC_APP_INFO_FETCH_FAILURE | Error retrieving application information. | |
| 1171 | API_EC_INVALID_APP_INFO | Invalid application information returned. | |
| 1172 | API_EC_PAYMENTS_APP_INSUFFICIENT_BALANCE | Application has insufficient balance (app2user). |
| Errornumber | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 800 | API_EC_DATA_UNKNOWN_ERROR | Unknown data store API error | |
| 801 | API_EC_DATA_INVALID_OPERATION | Invalid operation | |
| 802 | API_EC_DATA_QUOTA_EXCEEDED | Data store allowable quota was exceeded | |
| 803 | API_EC_DATA_OBJECT_NOT_FOUND | Specified object cannot be found | |
| 804 | API_EC_DATA_OBJECT_ALREADY_EXISTS | Specified object already exists | |
| 805 | API_EC_DATA_DATABASE_ERROR | A database error occurred. Please try again | |
| 806 | API_EC_DATA_CREATE_TEMPLATE_ERROR | Unable to add FBML template to template database. Please try again. | |
| 807 | API_EC_DATA_TEMPLATE_EXISTS_ERROR | No active template bundle with that ID or handle exists. | |
| 808 | API_EC_DATA_TEMPLATE_HANDLE_TOO_LONG | Template bundle handles must contain less than or equal to 32 characters. | |
| 809 | API_EC_DATA_TEMPLATE_HANDLE_ALREADY_IN_USE | Template bundle handle already identifies a previously registered template bundle, and handles can not be reused. | |
| 810 | API_EC_DATA_TOO_MANY_TEMPLATE_BUNDLES | Application has too many active template bundles, and some must be deactivated before new ones can be registered. | |
| 811 | API_EC_DATA_MALFORMED_ACTION_LINK | One of more of the supplied action links was improperly formatted. | |
| 812 | API_EC_DATA_TEMPLATE_USES_RESERVED_TOKEN | One …or more of your templates is using a token reserved by Facebook, such as {*mp3*} or {*video*}. |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 850 | API_EC_SMS_INVALID_SESSION | Invalid sms session. | |
| 851 | API_EC_SMS_MSG_LEN | Invalid sms message length. | |
| 852 | API_EC_SMS_USER_QUOTA | Over user daily sms quota. | |
| 853 | API_EC_SMS_USER_ASLEEP | Unable to send sms to user at this time. | |
| 854 | API_EC_SMS_APP_QUOTA | Over application daily sms quota/rate limit. | |
| 855 | API_EC_SMS_NOT_REGISTERED | User is not registered for Facebook Mobile Texts | |
| 856 | API_EC_SMS_NOTIFICATIONS_OFF | User has SMS notifications turned off | |
| 857 | API_EC_SMS_CARRIER_DISABLE | SMS application disallowed by mobile operator |
| Error number | PHP Constant name | Error description | Generated by methods |
|---|---|---|---|
| 1050 | API_EC_INFO_NO_INFORMATION | No information has been set for this user | |
| 1051 | API_EC_INFO_SET_FAILED | Setting info failed. Check the formatting of your info fields. | |
It is a matter of preference, no doubt, but most developers I know prefer monospaced fonts. So what are the best ones to be used?
Over the years, I’ve tried numerous fonts and the few that work good are Monaco, Menlo, and finally Ubuntu Mono. Menlo is a great font that comes with OS X and is used in X-Code. It is also the best font so far that I found
I have recently tried to work with Sublime Text 2. I have used TextWrangler before but Sublime seems so much more powerful out of the box. I read somewhere that it is possible to setup TextWrangler with various plugins and extensions to make it quite powerful too, but Sublime Text comes already quite powerful out of the box and just feels more natural. TextWrangler never really felt natural to me but it was the best option I had so far as it had more options than Smultron.
So I tried Ubuntu Mono with Sublime Text but it looks almost the same as Menlo and since I am using Menlo with Eclipse already (Ubuntu Mono regular was horrible in Eclipse) I decided to keep using Menlo despite many praises towards Ubuntu Mono. But Ubuntu might be a good alternative for other OSes that do not have the Menlo bundled with it.
Happy coding!